Bertrand Wilden
Blog
The NYC Rat Index
Blog
Categories
All
(5)
Bayes
(4)
GIS
(2)
R
(5)
Tutorial
(3)
brms
(2)
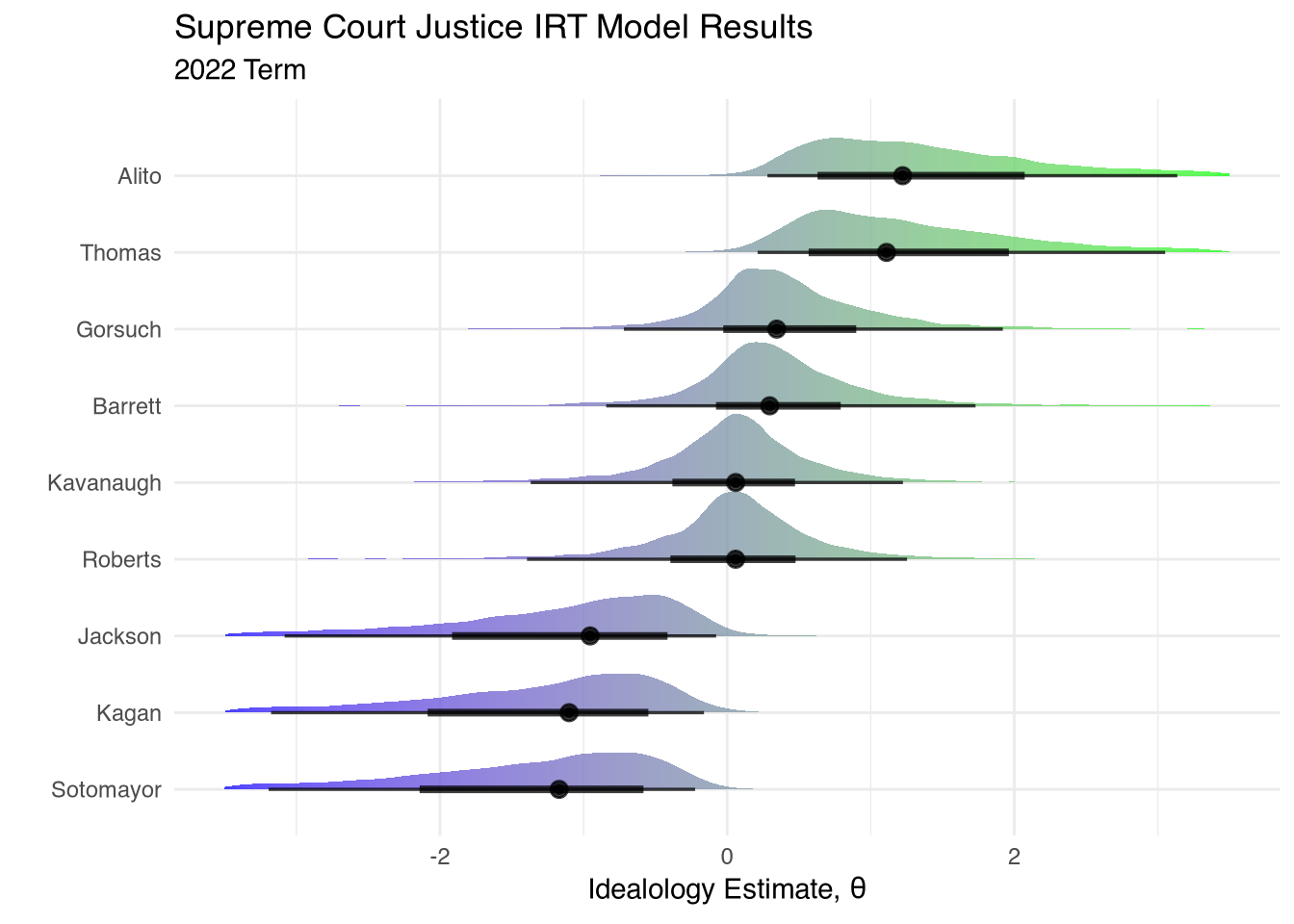
Practical Bayesian IRT Modeling in R
Bayes
Tutorial
brms
R
I spent a good chunk of my 5-year Political Science PhD attempting to estimate the ideology of various groups and individuals. During this time I developed a workflow for…
Jun 13, 2024
Bertrand Wilden
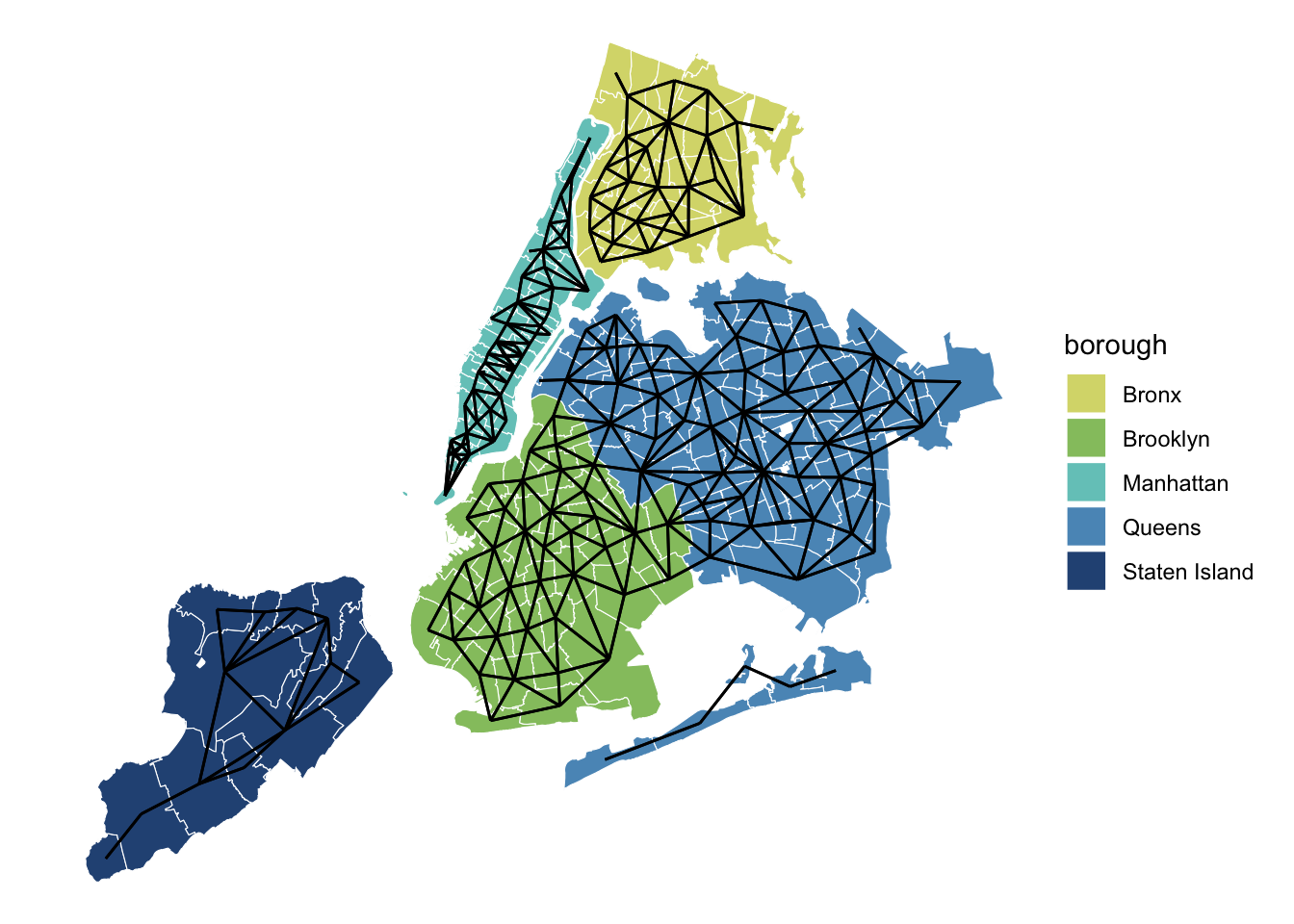
The NYC Rat Index
Bayes
GIS
R
Rats are “public enemy number one”—at least according to New York City Mayor Eric Adams. Last year the city established a “Rat Czar” who has been tasked with detecting and…
May 29, 2024
Bertrand Wilden
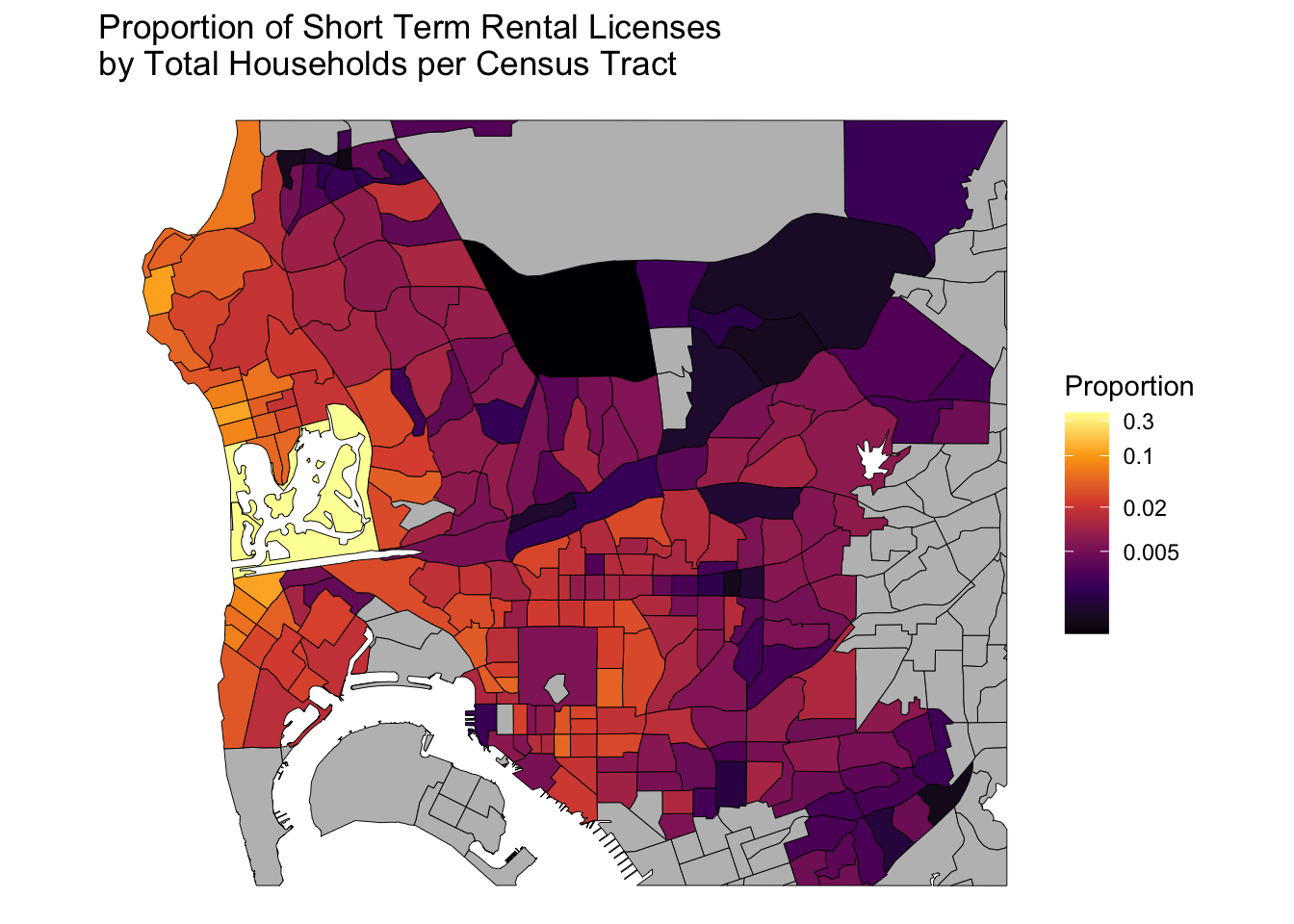
Mapping Airbnbs in San Diego
GIS
Tutorial
R
About a week ago on the r/SanDiegan subreddit someone posted a link to new data from the City of San Diego on Short-Term Residential Occupancy (STRO) licenses. These data…
Jul 31, 2023
Bertrand Wilden
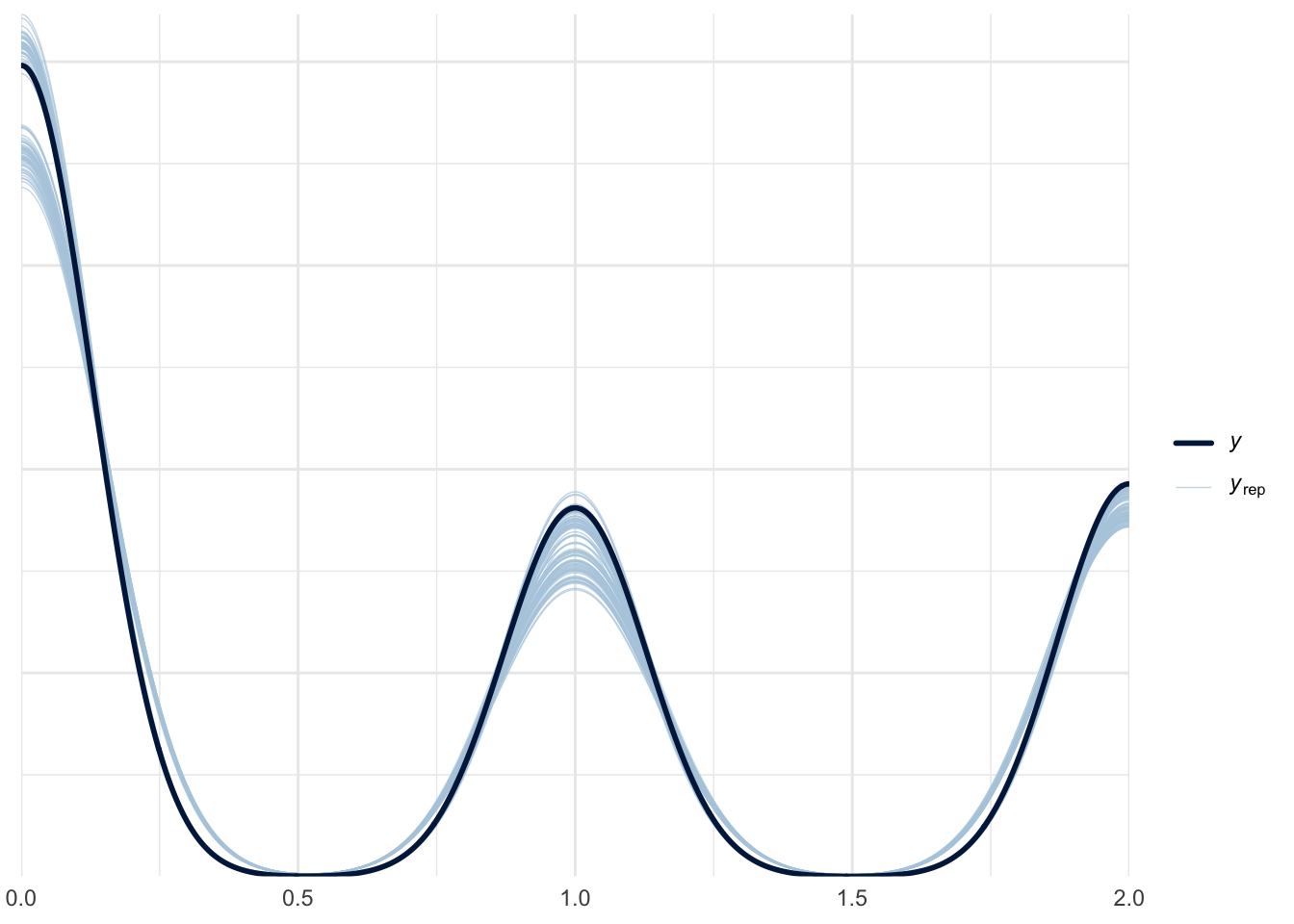
Probing the Depths of Probit Regression
Bayes
brms
Tutorial
R
When do you use a probit model in statistics? When you have some data and want to probe it for answers!
Jun 21, 2023
Bertrand Wilden
Does Height Matter When Running for President?
Bayes
R
Height is supposed to confer all sorts of advantages in life. Taller people make more money, have an easier time finding romantic partners, and can reach things off the…
Aug 9, 2022
Bertrand Wilden
No matching items